

Here is the list of SAP S4HANA interview questions. These SAP S4 HANA interview questions are designed to educate an SAP Consultant about basics of S4HANA questions so that consultant can address queries raised by client and participate in internal organizational meetings. In any S4HANA interview these questions can be asked. Sometimes while conducting client workshops such questions can be asked by client also. These S4 HANA interview questions will help in such preparations.
1. What is meaning of S4HANA?
Ans. This is a common S4HANA interview question. In SAP S4HANA there is a meaning of S4HANA. Here you go:
- S – Simplified or Suite Data model of SAP
- 4 – Fourth generation ERP technology
- HANA – It is built on in-memory data base platform
HANA stands for High performance ANalytical Appliance. It is a database which stores data in its memory instead of main disk.
2. What are key features of S4HANA?
Ans. SAP S4HANA key features are as follows:
- In-memory data base platform: S4HANA is an in-memory data base platform.
- Better user interface (UI) – SAP Fiori
- Choice in Deployment – On premise, Private Cloud, Public Cloud and Hybrid
- Simplified Data model – merger of Tables into one single table
3. What do you means by in-memory data base platform?
Ans. In-memory data base means that the capability to store huge data on RAM. Availability of large amount of data in RAM means fast speed because RAM is close to CPU (brain of a computer). This helps in faster data processing while executing enterprise transactions. Please note that data processing is thousands times faster on RAM than on a hard disk.
4. What are the benefits of HANA database?
Ans. Here are the benefits:
- In-memory => HANA database is in-memory which ensures a faster speed because large part of data is stored on RAM. Size of RAM is in terabytes
- Parallel Processing => There is massive parallel processing of data using multiple cores.
- Fast processing in Columnar Data Storage => Data in the HANA database should be well structured for a faster transaction posting. Therefore, Data is compressed by several times and maintained as column storage. A columnar storage ensures a well regulated compression. Data processing is fast in it because no indexing is required.
- Reduction in Data footprint => No indexing is required in database because data is stored in columnar storage. This eleminates many tables in database. Only useful and necessary data is available on in-memory (RAM). Remaining goes to disk. Lot of hybrid and aggregate tables are convered into one single table in HANA. This simplification results into reduction in data footprint.
- Application services on HANA database => The business application program is also handled on the HANA database. So no separate application server is required. In SAP ECC there was a separate application layer where we were writing the program but here we can handle the application (or program) on database. Please remember that Application, program, services and business logic, all are same.
- Different type of data handling => HANA database can handle different type of data such as spatial, graphical, text etc. Spatial data is the data related to maps which includes longitude and latitude.
5. What does ‘4’ indicate in S4HANA?
Ans. 4 in S4HANA indicates fourth generation ERP technology. It can be a spontaneous question in interview or client can ask this.
6. What is multicore parallel processing in HANA Database?
Ans. Multicore parallel processing mean data procesing such as calculations, analytical joins, aggregation are done in parallel. Data is being read from columnar data base which is faster than row data base. Please refer below diagram for reference. This diagram show how multiple cores Core 1, Core 2, Core 3 and Core 4 work in parallel and makes things faster.
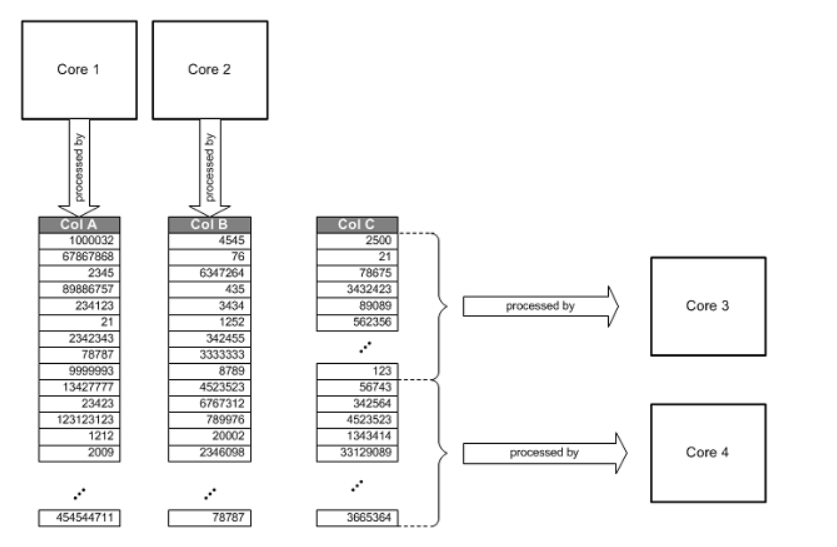
7. What are benefits of columnar data storage or column-based storage in HANA Data base?
Ans. Here are the benefits of columnar data storage:
- Better data compression: When data is stored column-wise, it can be compressed efficiently. This is because similar values often cluster together, especially in sorted columns. Compression techniques such as run-length encoding and cluster encoding can then capitalize on these patterns, leading to significant space savings.
- Better performance for column operations: Single-column operations such as searching in columnar databases works well by using array-based loops over contiguous (or adjacent) memory locations. This high spatial locality works efficiently with CPU caches, boosting performance to warp speed.
- Removal of additional indexes: Columnar database and in-memory access in SAP HANA often make additional indexes redundant due to high scan speeds and effective compression. This results into reduced memory footprint, improved write performance, and reduce development efforts. However, indexing is not entirely absent: primary keys remain indexed, and additional indexes can be created for specific queries.
- Removal of materialized aggregates: High column-scanning speed makes it possible to calculate aggregates on large amounts of data faster. This eliminates the requirement for materialized aggregates in many cases. Eliminating materialized aggregates has several advantages. It simplifies data model and aggregation logic, which makes development and maintenance more efficient; it enables the concurrent table update without locking the tables while updating them and it ensures that the table aggregated values are upto date without any locking. For example: MSEG and MKPF are replaced by MATDOC.
- Parallelization: Columnar database simplifies parallel execution of different transactions in same table using multiple processor cores. In a column store data is already vertically partitioned. That means transactions on different columns can easily be processed in parallel. This saves time and execution becomes faster.
8. In S4HANA Database, the table aggregates are removed. What does it mean? What sort of problems did aggregates created in database?
Ans. In SAP when we post a transaction then tables get updated at item level where we have aggregates such as Sum of quantity, currency or average of numeric values. These values are stored in aggregate tables. When we run any query to pull this data at that time our program brings values from these different aggregate tables which make the system slower. The main drawback of aggregate tables is data redundancy in data storage and time laps between data update and last aggregation of data. Therefore, S4HANA database allows to change the data model in a way to avoid such aggregates (helper) tables.
For example: Please check following example:
- MSEG and MFPF tables are merged into MATDOC table
- BSEG and BKPF tables are merged into ACDOCA table
9. Does it mean that we cannot see MSEG, MKPF tables in SE11 and SE16N?
Ans. S4HANA Data model allows change in the data model, it does not mean that MSEG and MKPF tables are removed from data base. You can still go to SE11 and SE16N and see the table and data. S4HANA gives the flexibility to change the data model.
10. What are different ways to implement SAP S4HANA in an enterprise?
Ans. There are three ways to implement SAP S4HANA in an enterprise:
- New implementation of SAP S/4HANA (Greenfield Implementation)
- System conversion to SAP S/4HANA (Brownfield Implementation)
- Selective data transfer to SAP S/4HANA (Bluefield Implementation)
11. What is Fiori in S4HANA?
Ans. Fiori is a design principle introduced by SAP to give a better user experience while using various applications to post transactions, run reports etc. Whenever this question is asked in S4HANA interview or any client workshop the first word that should strike in your mind is “design principle” and second word should be “better user experience“. Rest you can handle.
12. What are different types of Fiori Applications in S4HANA?
Ans. There three types of Fiori applications provided by SAP.
- Transactional Apps
- Fact Sheets
- Analytical App